

Ground truth
Extracting ground truth form virus-total
In order to get some feeling of how well the clustering can be performed a very simplistic ground truth is needed. One approach is to make a count of virus-total predictions about the malware type and family. Preliminary results can be found below.
Virus-total count plot:
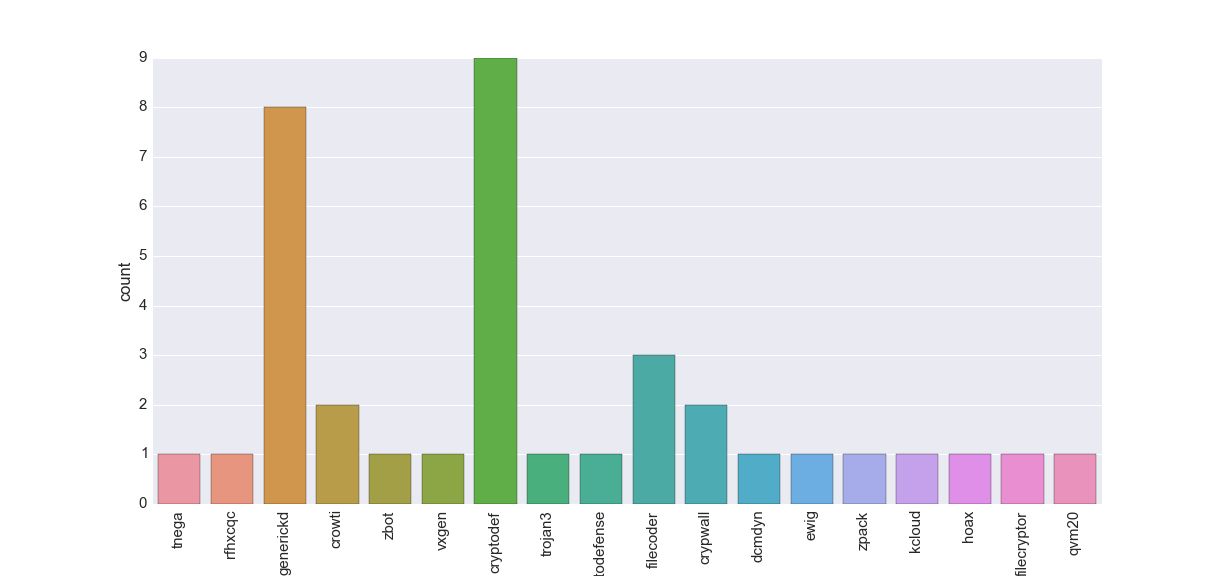
A more advanced approach is to take a malware name and split it into more general names; the count plot shown below depicts this approach.
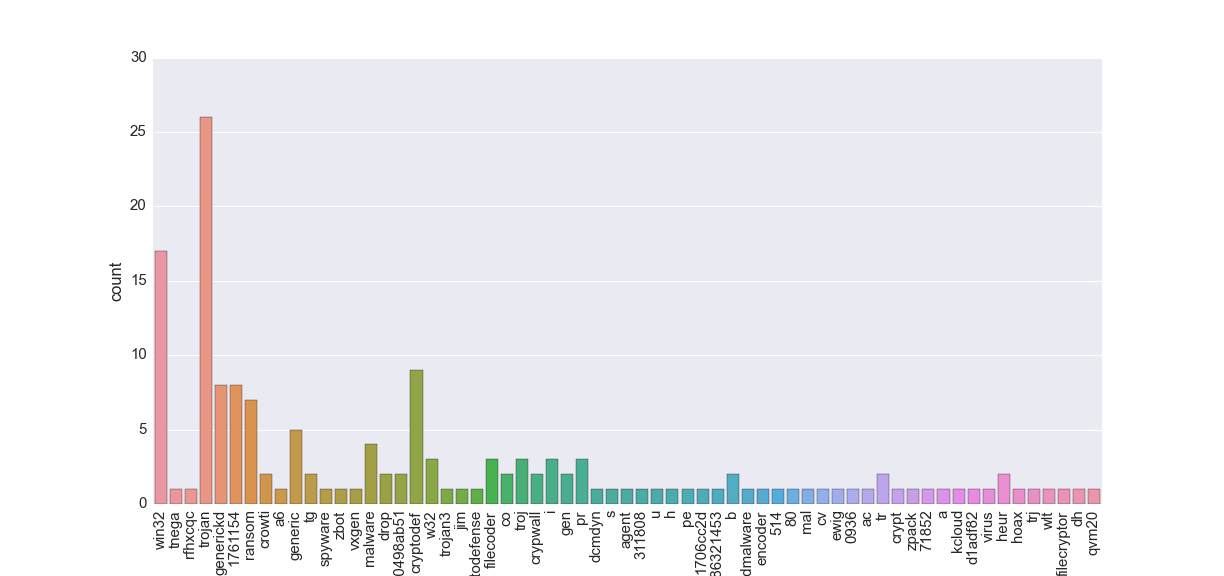
The first approach is very simple but it may not necessarily be right due to different variations in malware naming. A more robust approach would be to use presented above bag of words based on the malware name and do some kind of string similarity checking e.g. Levenshtein distance.
For instance on the latter plot generickd, generic and gen should be treated as one.
Is it worth the effort?